
© Behavioral Informatics &
Interaction Computation Lab.
All rights reserved.
Interaction Computation Lab.
All rights reserved.








事實上,電影有著歷史資料數量龐大的特性,讓票房預測變成機器學習或資料科學的最佳題目之一。除了歷史上的票房數據,可供機器學習的資料包括上映季節、年份、出演明星、電影類型等等。
大家都知道,這年頭預測電影票房早就不是新鮮事了。早在 2013 年,Google 就曾經發表報告,利用搜尋排行及預告片觀看次數等資料,預測電影上映首兩周的票房。到近兩年,因為AI領域的機器學習研究推進,甚至有以劇本來預測票房的人工智慧黑科技!
而這篇文章要討論的創新角度,就是利用新媒體與新文化中展現的人類行為加入預測中。隨著時代推進,近幾年也開始出現以個人為單位的新媒體,不得不說,這些新媒體無奇不有,人們似乎以觀看他人做各式各樣的事為樂。這些 Youtuber 觀賞預告的反應,引起網友們共鳴,間接地透露出電影帶給觀眾的共同情感與意義,也讓人不禁猜測是否這些 Youtuber 的表情隱隱揭露電影受眾的體驗和喜好。BIIC Lab 的碩士生柯明亞讓電影票房的預測加入了嶄新的元素:Youtuber 錄下自己觀看電影預告片時表情的影片。
在 Youtube 搜尋「trailer reaction」後,會出現許多 youtuber 的反應影片集結。
在電影產業中預測票房,通常著重於上映首周,因為首周上映的票房可能牽動片商後續的財務規劃。研究顯示,首周票房的收入占了電影總票房的 25%,並且上映的首周周末,更是影響戲院經理決定是否要讓影片繼續佔據檔期的關鍵。
影響電影票房的因素相當多元又複雜,現存的電影票房預測逐漸採用大數據分析,相關研究曾運用預告片的視覺及音效或擷取其他預告片特色來評估觀眾偏好,另外 Twitter 用戶及部落客的即時評論也能揭示票房走向;甚至包括維基百科的造訪次數,都提供評估電影預測的能量。另外,數據分析用於探知觀眾感受也是備受重視的應用,曾有研究人員模擬觀眾觀影的情緒,他們利用的是醫學訊號:眼球反應、凝視距離、EEG(腦電圖)回饋。
這些被電影觸發的感受與情緒,尚未被納入預測模型中,觀眾沉浸於觀影經驗時,表情就揭露了最真實且直接的想法,Youtuber觀影的反應也常間接呼應了文字評論及其他媒體。因此,明亞嘗試架構一個納入人類自然反應的模型。在這次的文章中,我們將介紹利用電影大數據、預告影音內容,以及觀眾在 Youtube 上自發性的影音回饋提出一個新的票房預測架構。這個架構的特色還有利用「最小化類別內投影距離」的前瞻技術,提升預測精準度,並在最後的成果中達到不錯的成績。
明亞從 Youtube 上蒐集了 2015 到 2018 年間 112 部電影的 175 支預告、並配合這些預告,找出 Youtuber 觀賞預告的影片,以此為基礎進行大規模的分析。
針對每一部電影,明亞從網頁 Box Office Mojo 撈取出的電影大數據中每一個變數如下:
接著是預告片本身的特徵做為變數:
最後是預告片觀者情緒反應影片中的變數:
預告片的內容以及觀者的表情都會被電影的類型影響,例如,觀賞劇情片和喜劇片的表情差異可能頗大。為了解決這個誤差,明亞利用深度學習模型來最小化類別內投影的方法:將預告片及觀者影片中取出的變數依據各自的電影類別來分組,進而讓電影類型造成的影響最小化,提升預測精準度。
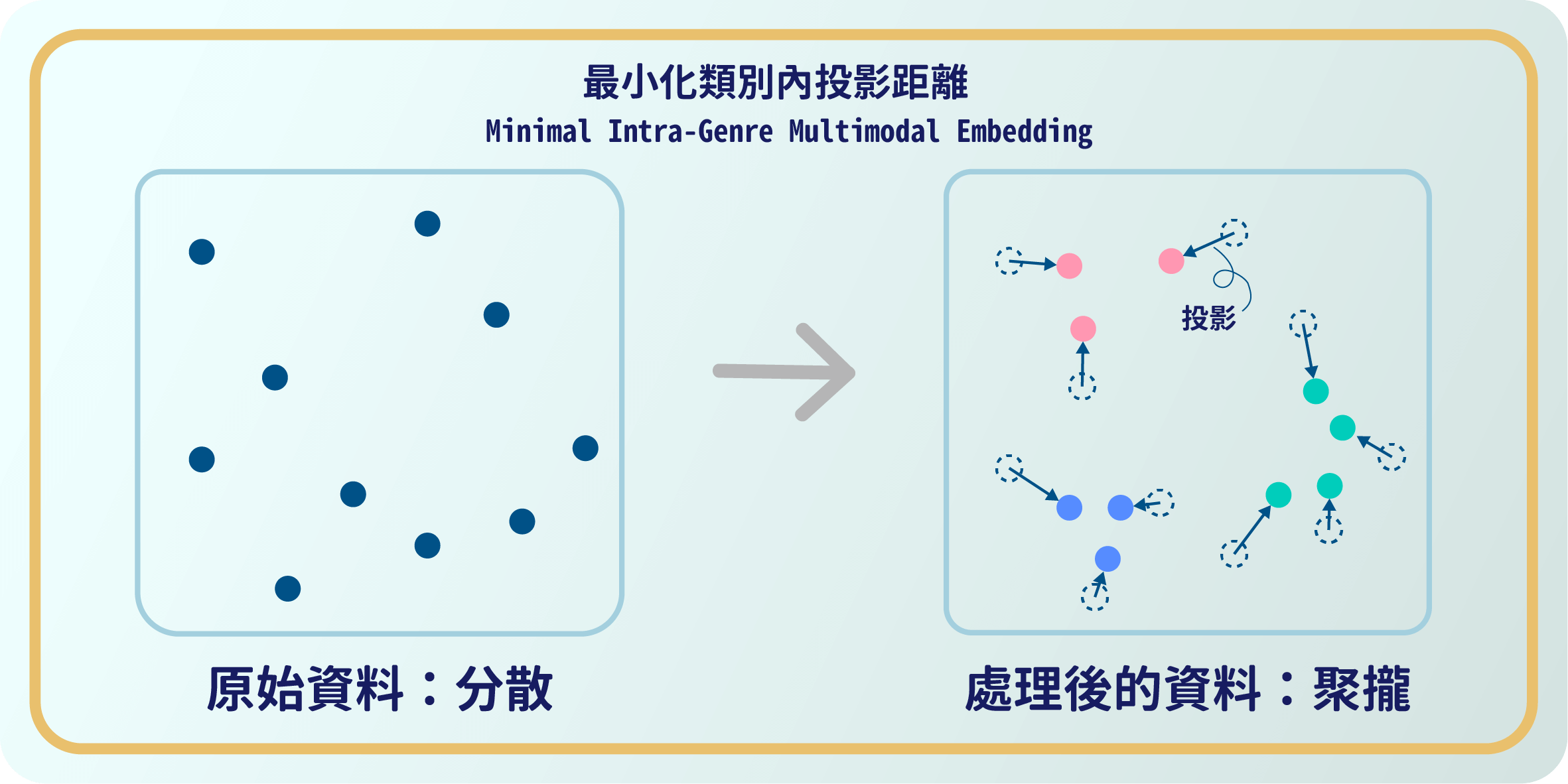
最小化類別內投影距離說明圖片:可看見處理後分散的資料能夠依類別聚攏。
接著,明亞利用 ANOVA 特徵選擇器(feature selection)的支撐向量機(SVM, support vector machine)來進行特徵的篩選,畢竟看看上一段,有那麼多的特徵,真正會影響到預測結果的、最重要的特徵到底是哪些呢?
將數據經過重重的整理與篩選,總算可以來讓機器分析囉!
明亞從網頁 Box Office Mojo 取得首周周末票房數據(經通膨調整),以收集到的數據分布,這其中票房最佳的電影是《星際大戰:原力覺醒》。
若以電影類型來區分,進行最小化類別內投影距離後,以喜劇片和恐怖片的預測效果最差。推測是由於這兩種類型的電影預告片與實際電影內容較容易有差異造成的,例如:喜劇電影預告片通常將笑點剪輯的非常密集,而實際電影中並不是全都是笑點。而在音樂戲劇類、動畫類、科幻奇幻類則使預測精準度有所提升。
而分別利用不同的資料組合來比較預測結果的準確率,透過下表可看到實驗成果,其中,可明顯看出,比起僅使用大數據及預告片特徵,再加入觀者表情為資料的預測可讓準確度更高。將資料進行最小化類別內投影距離,也比未執行更能達到精準預測。綜上所述,將觀者表情及預告片資料進行最小化類別內投影距離並加上電影大數據這一組和的表現較其他組合表現最佳,在預測中可以達到73% 到79% 的準確率。
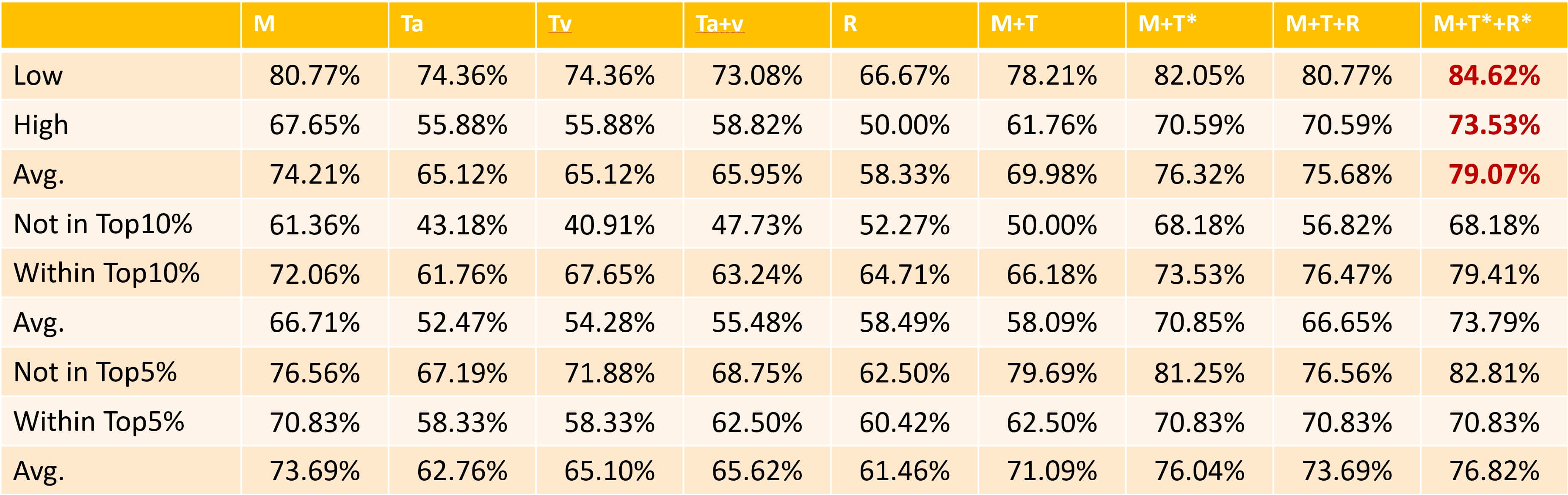
明亞以多種不同組合實驗預測票房準確率,票房有三種分類方式、實驗使用的資料組合主要以是否使用最小化類別內投影距離為區分。
表中M=metadata,Ta=trailer action,Tv=trailer voice,R=reaction,*=使用最小化類別內投影距離。
透過本文,我們可以瞭解到資料在預測票房中舉足輕重,除了擁有龐大的資料庫以外,如何精準的整理並利用資料也非易事。實驗結果顯示最小化內部類別投影的確能夠提升預測精準度,並且將製作方及觀眾方的觀點都加入實驗中,也是第一個將觀眾即時反應當作預測元素的大規模實驗。或許未來研究者們會在新興媒體中挖掘出更多可用的資料,讓預測精準度再一次提升。
不過在那之前,或許你已經看過 AI 寫的劇本、你的觀影選擇早已被預測中了!
本文改寫自碩士生柯明亞 2019 年於 ICME 發表的論文:
Ming-Ya Ko, Jeng-Lin Li, Chi-Chun Lee, "Learning Minimal Intra-Genre Multimodal Embedding from Trailer Content and Reactor Expressions for Box Office Prediction", in Proceedings of the IEEE International Conference on Multimedia & Expo (ICME), 2019

本文介紹的論文第一作者,清華大學 BIIC Lab 碩士生柯明亞,攝於 SP‧ARK。