© Behavioral Informatics &
Interaction Computation Lab.
All rights reserved.
Interaction Computation Lab.
All rights reserved.










隨著機器學習、深度學習的發展,機器已經能夠在單一任務上取的非常優異的表現。然而,機器與人類仍有本質上的差別,那就是快速學習新事物的能力。想像嬰兒時期的我們面對新環境時已有一套本能的機制處理,再由環境給我們的回饋,我們可以快速的把之前的知識套用在新問題上面。為了讓機器也有這種「知道如何學習」的能力,Meta-Learning(元學習)的概念開始發展。與一般的深度學習或強化學習最大的差別在於元學習會先學習一個先驗知識,以利於面對先的任務時能夠適應得更快更好。在本篇部落格中,我們將透過三個面向(Gradient/Loss/Architecture)來一窺 Meta learning 的技術發展。
Meta Learning 最常被用來解決少樣本(Few-Shot)的問題,在這邊我們介紹一篇經典的論文 Model-Agnostic Meta-Learning(MAML)。由題目可知他是一種「與模型無關的」元學習,亦即這種方法可以匹配任何使用梯度下降算法(Gradient Descent)訓練的模型,並能應用於各種不同的學習問題,如分類、迴歸和強化學習等。
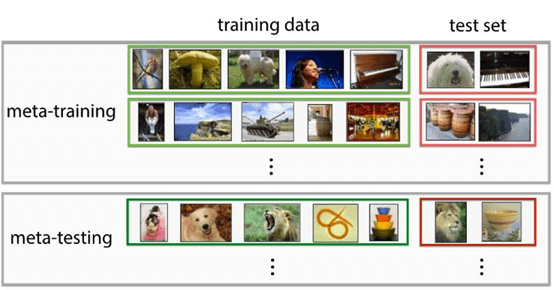
在進入這篇論文前,先來談談元學習中資料的部分,一般我們在 Deep Learning 或是 Reinforcement Learning 中的訓練集與測試集在 Meta Learning 中稱為 Meta-training 與 Meta-testing。而在這兩個集合中又再分為training data與 test data。
在 MAML 中,其目標在於一次看過多種任務(task),並希望可以學到一個可以找到所有任務「本質」的模型。舉例來說,我們小的時候學會寶特瓶可以一手握著瓶身,另一手將瓶蓋轉開;而當我們接觸到一個裝糖果的玻璃罐時,我們察覺玻璃罐與保特瓶相似的本質,因而有辦法套用既往的知識快速的移轉到新的任務上,而MAML便是在學這個過程,在遍覽多種任務後,學習一組對任務敏感的參數,當新任務進來時能快速的將先驗知識移轉到新任務中。

其演算法如上圖所示,分成3個步驟:
最後當 MAML 的模型訓練完成後,利用 meta-testing 驗證。 Meta-testing 中所有的任務為model從未看過的任務,為了能 adapt 到新任務中,先使用 training data of meta- testing 對模型做微調(finetune),最後便可用test data of meta-testing驗證效果。
綜觀上述,MAML 提出的是一種計算不同 Tasks 之間 gradient 的方法,而此方法是通用的,可套用在分類(Classification)、回歸(Regression),甚至是強化學習(Reinforcement Learning)中,我們只需要改變 loss 計算的方式:
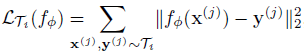
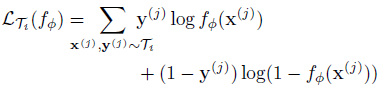
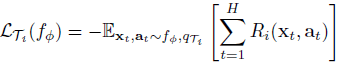
本論文中也分別實作回歸、分類和強化學習,在回歸的應用中,他們希望實現少少的樣本點便可描繪完整的 sin 波。在這邊他們定義的不同 task 代表不同振幅、不同相位的sin波,而他們使用的 meta-training set 便是對每個 task(即一組振幅和相位下)隨機取樣 10 個點作為訓練集。因此訓練的過程中,MAML 會看過許多 tasks 的一些 samples,並試圖找出他們的本質;在測試的時候,他們希望可將上面學得的知識快速套用在新的 sin 波上,因此,他們的 meta-testing 的 training set 為從這個新任務中隨機 sample K points(本文中 K=5 or 10)對 MAML 的模型 finetune,而預測的結果如下:
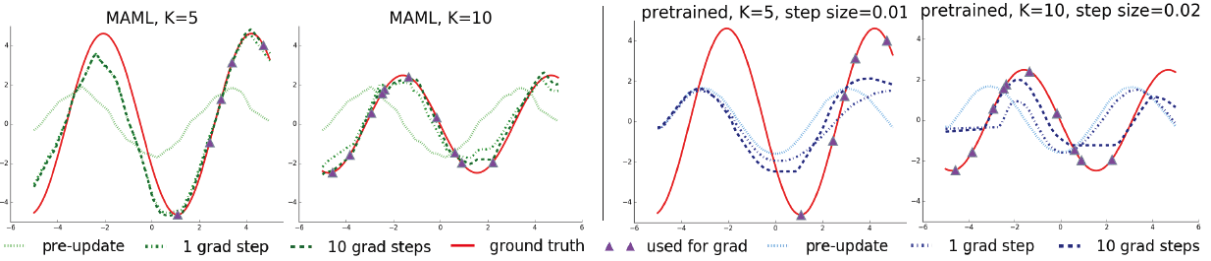
其中,1 grad step 可想成 finetune 時只 finetune 一個 epoch,同理,10 grad steps 則是 finetune 十個 epoch。上圖中左邊兩個是 MAML 的結果,右兩個是本文這個實驗比較的 baseline,亦即先 pretrain 好所有的樣本點再做微調。可以發現透過 MAML 學習先驗知識可以利用 K 個 samples finetune 快速的適應新的任務;而利用過去的 pretrained method 可發現預測出來的結果仍停留在不同的任務中或是開始偏離 sin 波的形狀。
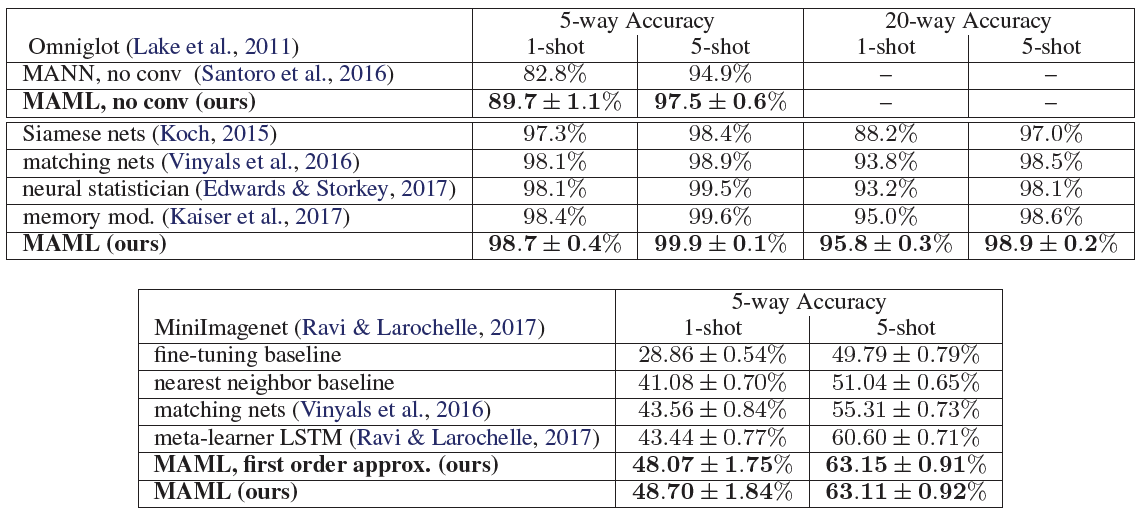
在分類任務中,作者們驗證在兩個資料庫:Omniglot 和 MiniImagenet,其中前者是一個字母符號的資料庫,裡面共有 1623 種文字符號,每種都由 20 個不同的人臨摹,在實驗中取 1200 個文字類別作為 meta-training ;後者是小型的 Imagenet 資料庫,裡面包含各式各樣的圖片類別,在這邊使用 64 類的圖做當作 meta-training。
在強化學習的實作中,可直接看他們的影片便可知道 MAML 的能力有多驚人囉!
既然 Meta leaning 是想要學習不同任務之間共通可以遷移的知識,那是否在不同任務的 model 之間加入一 Meta 網路即可達到想要的目的呢? “Learning to Learn: Meta-Critic Networks for Sample Efficient Learning” 這篇論文就利用了此概念來達成 Meta Information 的學習。
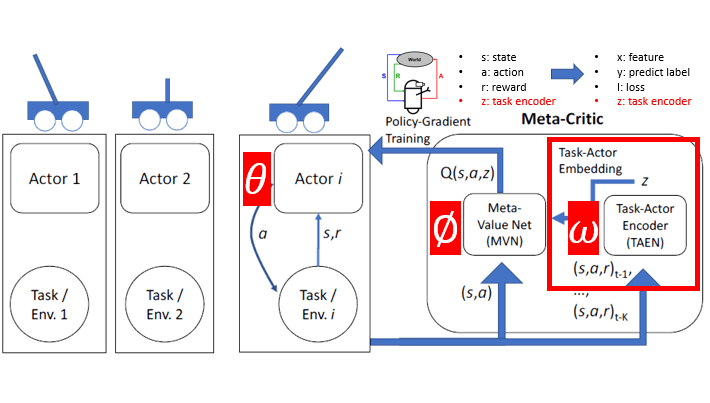
此篇論文大致上跟隨 Reinforcement learning 上 Actor-Critic 的概念,利用分散式的 Actor 網路(policy network/classifier)與單一的Meta Critic網路(Meta Value Net+Task-Actor Encoder),來學習不同任務之間的關係。值得注意的是,此網路與上述的MAML一樣,是與模型無關的。也就是說,在此網路架構底下,Actor對應到監督學習的分類器/回歸器,每一個強化學習下之(s、a、r)對應到監督學習的(x,y,loss)。而參數更新的objective function 如下:
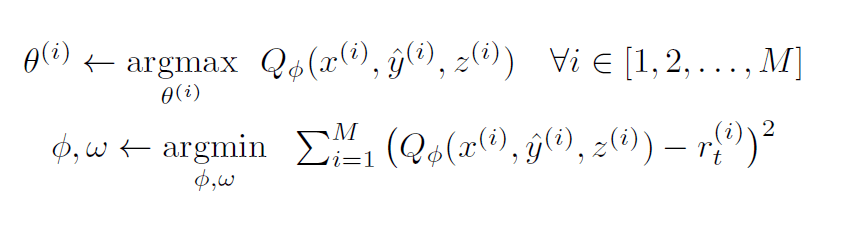
首先,是每一個Actor模型(對應到每一個task)的參數,而我們是透過最大化Q值
來更新我們的 Actor 模型,而不是原本監督學習之直接算出來的 loss 來更新,此為Actor-Critic算法最重要的精神。而現在的問題將會變成,要怎麼獲得一個好的 Q 值呢?因此很直覺的,更新 Q 值得方法將會是最小化與正常
的均方差,以期望我們的Q值能符合現實環境。而同時,我們可以看到 Q 值受到兩個參數影響:
是 Critic 網路的參數,而
則是用來 embedding 不同任務之間關係的 Task-Actor Encoder(TAEN)之參數。透過共同的更新這兩個參數,我們將能把不同任務之間的關係儲存在參數中。
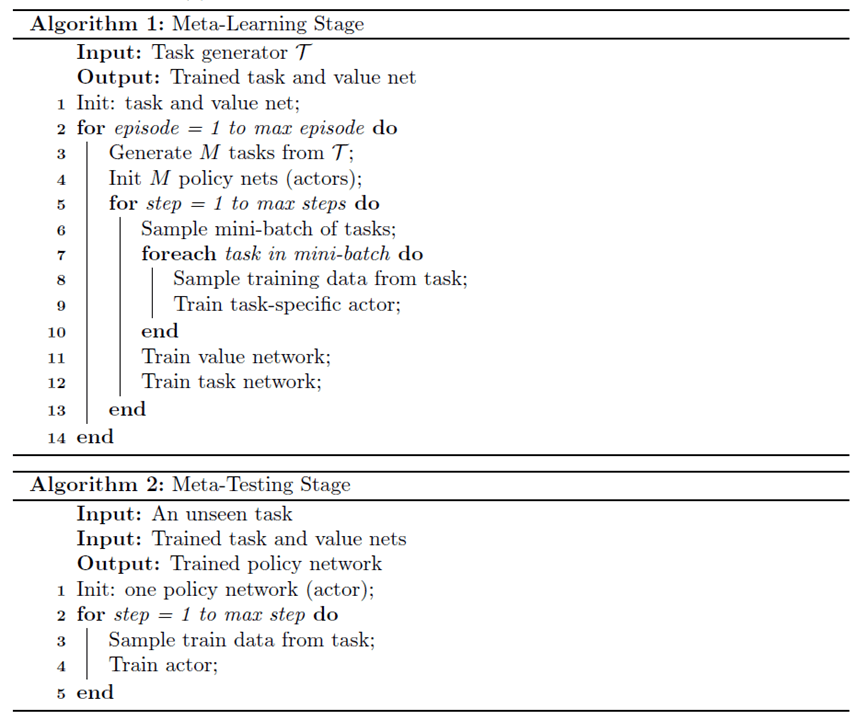
最後,在結束 Metal-Learning Stage 之後,當我們要 Meta-Testing 的時候,我們將會在新的任務上訓練一新的網路 ,而訓練的方法將會是透過 K-shot 的資料,輸入進 Meta Network 得到的 Q 值來訓練
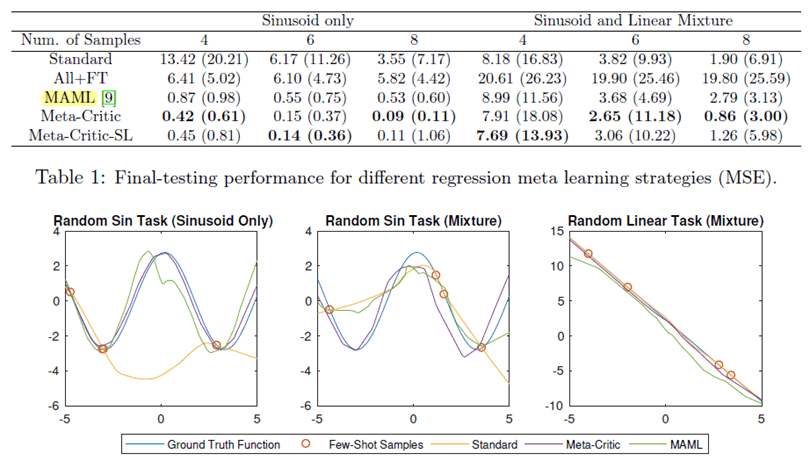
。最後,在本篇論文中跟MAML一樣,用一個合成的 sin 波資料集來測試知識遷移能力的好壞,結果如下(基本上就是大勝 MAML 啦!):