
© Behavioral Informatics &
Interaction Computation Lab.
All rights reserved.
Interaction Computation Lab.
All rights reserved.






在訓練各種機器學習模型或是類神經網絡模型時,都需要倚靠大量的資料庫來協助訓練,然而,並不可能對「所有」不同領域或是情況下的資料都蒐集完之後才來做模型的訓練。
為了讓模型可以更加 Generalize、同時因應各種不同領域的資料庫,因而產生了 Zero-Shot Learning 的演算法。 而 Zero-Shot Learning 演算法的概念其實就是在模仿人類學習的方式,人類在學習的時候其實會以概念的形式去做類推,以下圖來做說明:

當人類在學習的時候,可能看過部分貓的品種,人類學到的是貓的耳朵形式、體型、尾巴等…的概念,當今天遇到一個新的品種(最右邊)時,人類會去辨識出耳朵、體型、尾巴、毛等元素進而去推論出這應該是某種貓的品種,不會把牠認成狗或是馬。 由此可知,人類並不用看過所有的品種就能夠去推測出新的物種,也就代表人類是利用現有的知識中去做推測,而 Zero-Shot Learning 演算法就是試圖去模擬人類學習的機制。
- Domain Adaptation
- Semantic Space
- Data Selection
- Feature Normalization
在 Adaptation 的部分,介紹 Associative Adaptation 系列的論文[1],在此篇論文當中,最常被使用的 Domain Adaptatation 的 Loss Function :
在此篇論文當中,作者引進了新的 Associative Loss 來取代 Similarity Loss,將最終的 Loss 改為 : ,而 Associative Loss 被分為
(walker loss)及
(visit loss) 兩項來做討論,提到這兩項 Loss 前要先介紹一下以下幾項:
Similarity Matrix:
此項可以理解成兩個不同 Domain 的資料庫 A、B 之間做內積計算相似程度。
而此項則可以理解成給定一個 A 資料庫中的 Sample,去對所有 B 資料庫中的 Sample 去計算距離,同時把值轉換成機率的形式,等同於 A 資料庫各個 Sample 對於每個B資料庫中的 Sample 都有一個機率值。
仿上述的概念則是變成B往A的方向。
此項則理解成 A Sample 經過 B Sample 之後再回到 A Sample 後的機率值。
接下來介紹 Walker Loss 及 Visit Loss 如下:
其中的 Walker loss 的 概念就是 A 到 B 再回到 A 之後所找到的 Sample 理論上要與出發的 Sample 非常相似,如下圖:
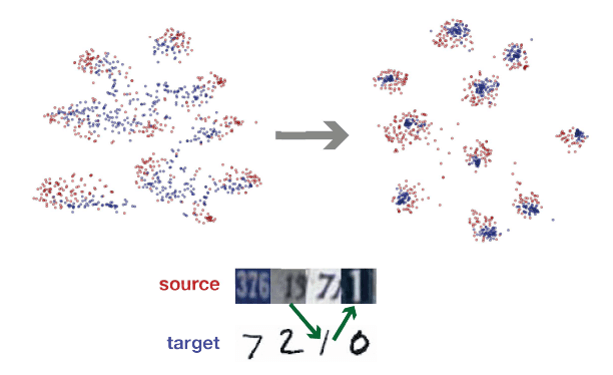
而 Visit loss 比較像是 Regularization Term 來限制從 A 出發的 Sample 尋找 B 資料庫的 Sample 時應該要以同樣的機率去做尋找。 結果如下圖所示:

Visit loss 左一為未經過任何 Adaptation,中間則是經過 Associative Loss 過後的結果,右邊是經過 MMD Adatation 過後的結果,可以看出 Associativ e的效果確實好了許多。
第二個要介紹的方法則是利用已知的 Semantic Space 的方法來對訓練資料庫沒看過的領域來做預測,這種方法最常被用在文字和圖片之間關係的連結,而這裡要介紹的論文[2]則是透過文字和圖片兩種 Modality 來做結合。
主要的概念如下: 藉由文字資料庫相對於圖片資料庫更好蒐集的特性,再論文當中也利用了前人已經訓練好的一個 Semantic 的文字模型來做精進,藉由已經訓練好的 Semantic Space 的文字向量和圖片萃取出來的特徵向量做一個分布拉近的動作,透過將相似的 Label 和 Semantic 的文字拉近,對於沒看過的的類別也就可以對應到相近的 Smantic 的 Attibute,再透過這些 Attribute,就可以去預測出未知的種類。
因此在文字模型的空間當中,,在文字端,分為看過和未看過的文字向量,接下來透過文字的 Label 將訓練資料中的圖片除了生成圖片特徵向量外也生成一組文字向量。 再透過以下的 Objective Function 來拉近彼此之間的分布:
透過次 Objective Function 過後,從下圖可以發現到類似的類別會在周圍形成一群:
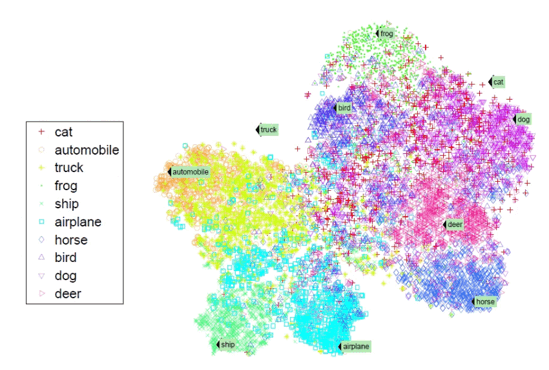
Objective Function 在此篇論文當中,作者也加入了他的小巧思,透過一個隱藏的隨機變數 V,將整個系統分成兩條路線,這個隱藏的隨機變數負責判別測試資料是否為看過的資料,若是看過的資料則直接透過 softmax 的 activation function 做預測,若是為未看過的測資,則是利用一個 Gaussian的 Discriminator 來做機率分布的預測。如下式:
此種方法必須要有一個已經富含許多資訊的模型才有辦法做如此的連結,並且透過這個模型所提供的資訊來對未知的類別作預測。
第三種方法則是相對直觀的方法,在接下來這篇論文[3]當中,在訓練資料當中尋找和測試資料相似性較高的來訓練一個新的模型。 在這篇論文當中,作者提到了 Prototipicality 的概念,在此篇論文當中是用到情緒資料庫來做說明,在這個情緒資料庫當中我們可以將 Arousal、Valence 都分為高低兩群,在這兩群當中分別可以取得平均值來當作群中心,這邊的假設是,理論上來說距離另外一類群中心越遠的資料應該要為較好的訓練資料。也就是較容易被區分正確的資料。如下圖:
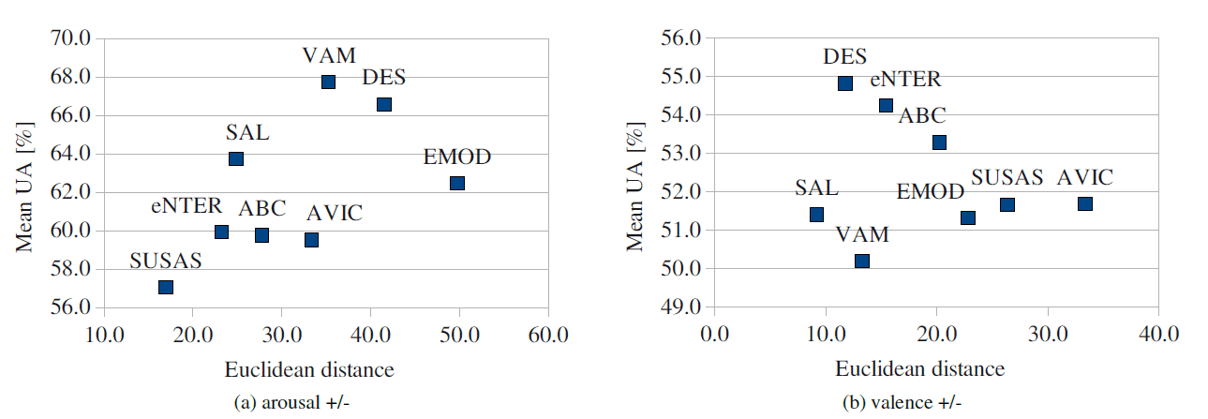
從圖中可以發現到本身資料庫當中的距離如果是越大的情況下,就會有越好的效果,不論是在 Arousal 或是 Valence 上都是如此,但如果仔細來看到 EMODB 的資料庫中,距離是所有資料庫中最大的,但是效果卻沒有 DES 來的好,作者在文中也提到了,雖然要選擇辨識度高的資料來當作訓練資料,但也要能夠 Generalize 到別的資料庫,否則像 EMODB 這種情況就是已經 Overfitting 自身的資料庫。 透過這個概念,作者在每一個情緒資料庫當中去計算 Euclidean Distance 來當作選取資料的依據。 在論文當中作者計算出所有 Sample 點的距離之後,變針對這個距離去做了一個排序的動作,在文中作者也設計了實驗針對要選擇多少 Percent 的資料來當作訓練資料,最後結果為 25% 的時候會有最好的效果。
最後一個常用的方法就是在 Feature 端動手,通常會造成個個資料庫之間無法通用的原因就是因為在 Feature Space 當中,這些資料庫的分布差異過大,或甚至不在同一個 Space 上,所以才會導致模型無法共用,所以接下來要介紹的這篇論文[4]當中,就是透過討論各種不同的 Feature Normalization 的方法來達到訓練出一個 General 的模型。 在此篇論文當中,討論了以下三種歸一化的方式:
- Centering
Substract feature- wise mean- Normalization
Min-Max normalization- Standardization
Z-normalization
此篇論文除了探討不同歸一化之間的關係,也討論了在不同的資料庫要整合一起去訓練模型的時候應該是要個別做完歸一化後整合做訓練,還是整合完再做歸一化又或者是整合前後都做歸一化的動作。 經過作者做了一連串的實驗後發現,如下圖:
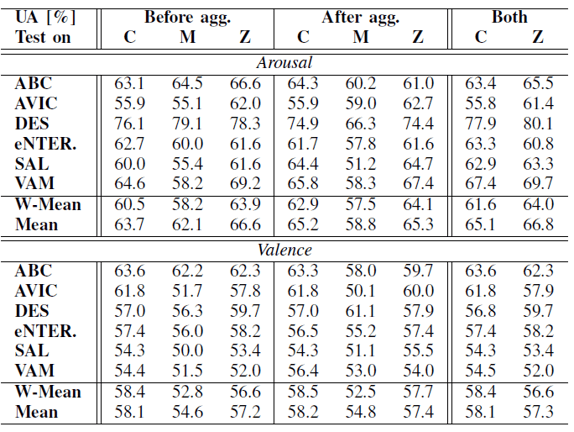
從上圖可以發現各自資料庫做完歸一化之後再合併,最後再做一次歸一化的效果會是最佳的,然而在概念上去理解這樣的解果則可以解釋成個別歸一化之後可以去除資料庫內各個樣本之間的差異,而合併之後再進行第二次的歸一化則是消除資料庫之間的差異,進而造成更好的效果。
在以上各種常用的手法當中,其實都有一些基本的假設和概念存在:
然而要進行以上的實驗都必須要達成一個最重要的前提,也就是要找到共同的分布空間,否則以上的演算法也不會達到如此的成效。
最後,除了介紹Zero-Shot Learning演算法的演進同時在最後我們也提供了一個有別於以往想法的演算法給大家做參考。下一篇要介紹的是一篇 2018CVPR 的論文,A Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts.